发表自话题:一分钟k线技巧
本期导读
本文分享如何使用Pandas的resample函数来快速转换1分钟数据到日k、30分钟K线数据,并详细解释在使用不同参数时的细节差异。
在量化中,数据是我们打交道最多的东西,不同的策略要用到不同时间级别的数据,比如有的用的是日k,有的用的是30分钟,60分钟k线,还有用5分钟的。而我们获取的数据一般是1分钟级别的,所以要先把他们做预处理。常规的预处理就是把我们获得的1分钟csv文件转换成我们需要的时间级别的hdf5文件。
把csv转换成hdf5的好处可以看我以往的文章
Python里面转成hdf5最常用的数据处理库就是pandas,他有非常多的功能,其中就有一个方便的resample函数可以方便地转换1分钟数据到其他时间级别的数据。
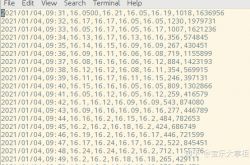
我们用到的原始1分钟数据是csv,用vim打开如下图,数据一共8列,分别是日期,时间,开高低收量金额。
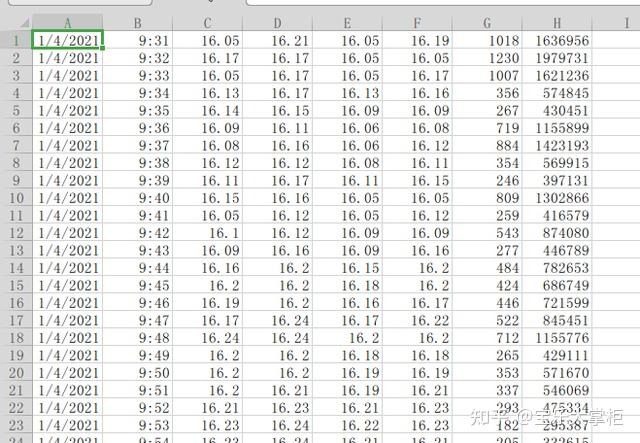
用excel看更清楚一些,这是某个股票2021年开始的1分钟数据csv文件。
转换成1分钟dataframe的代码如下:

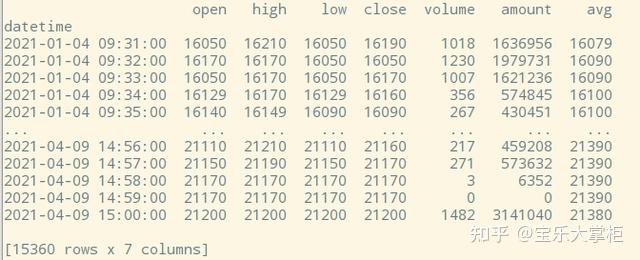
做出来的dataframe是这样的。这里面数字都很大是因为我乘以了1000,以方便压缩,在文末的相关文章中有详细介绍。
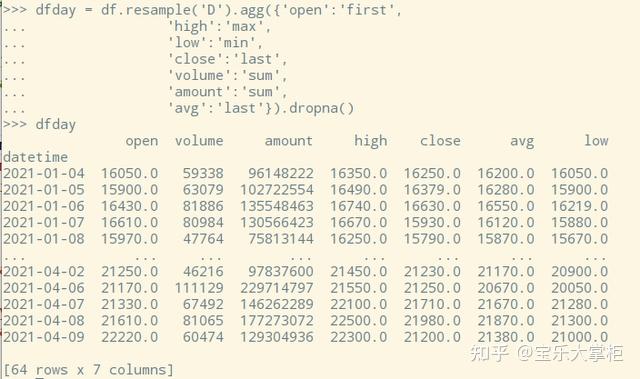
接下去就是转换成日k,用pandas的resample函数即可,非常好用。下图的df_1min就是上图做出来的dataframe。

注意resample的参数是("D")这个代表day,也就是日k。
转换出来效果如下:
那么要做成30分钟呢?把"D"改成"30min"就可以了。

转换出来的效果如下:
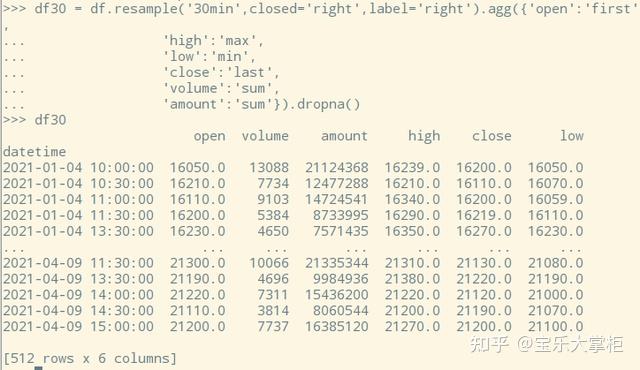
注意代码里面比上面做日k多了两个参数closed和label,这是非常关键的两个参数。
让我们来看看文档
closed{‘right’, ‘left’}, default NoneWhich side of bin interval is closed. The default is ‘left’ for all frequency offsets except for ‘M’, ‘A’, ‘Q’, ‘BM’, ‘BA’, ‘BQ’, and ‘W’ which all have a default of ‘right’.
文档中的bin其实是数据分析中的术语,也就是一个切割出来的数据块。closed指的是这个bin的切割点在哪里,在我们的例子中,就是决定第一个半小时的最后一条数据是9:59还是10:00。
为了方便演示,我们取最后一天的240分钟数据。
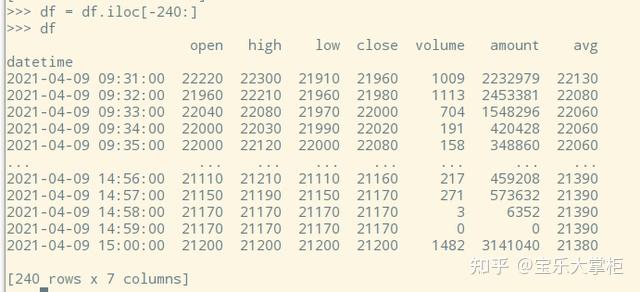
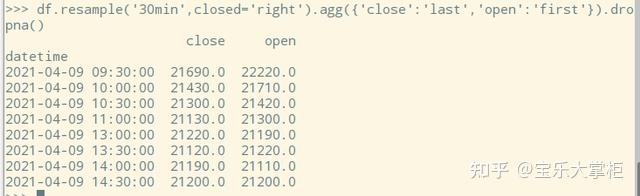
看一下第一个半小时的数据,注意其中的时间索引,是从9:31到10:00,也就是这些数据应该组合成一个30分钟k线,这个半小时的收盘价应该是10:00的close,也就是21690。
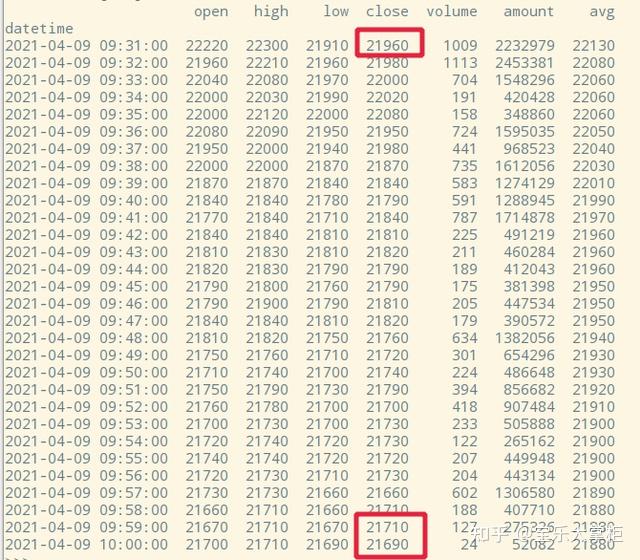
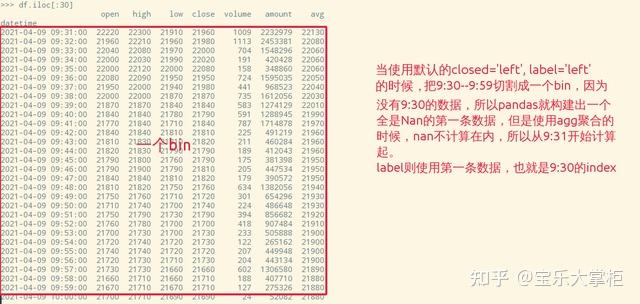
我们先用默认参数,也就是closed='left',label='left'来做,做出来的结果不是我想要的是吧,数据变成了10个半小时,而我们一个交易日只有8个半小时,并且然后第一个半小时的收盘价都错了。
这是因为closed这个参数是用来切割数据分块的。默认的closed='left'实际上是把9:31-9:59切割成第一个bin,并且他认为数据漏掉了9:30,所以加上了一个9:30的索引。所以close这个值用的是9:59的,而不是10:00的。
这样一来,11:30这最后一条数据,也独立地成为了一个半小时k线。因此整体就多了2根30分钟k线。
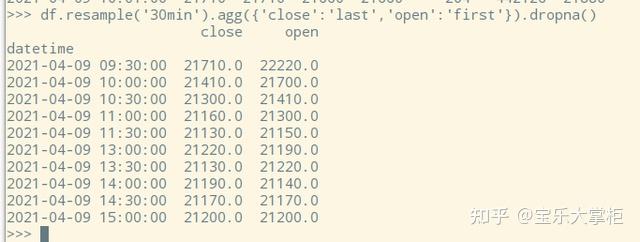
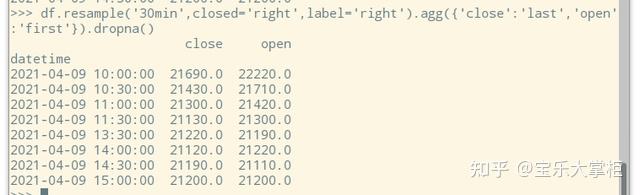
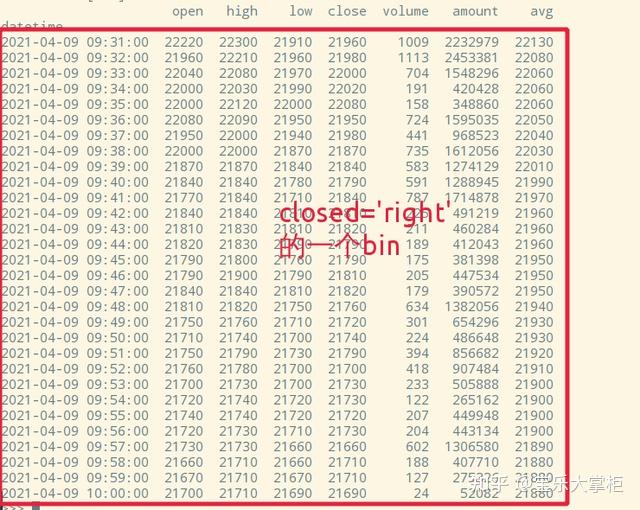
我们把closed='right’参数加上,这回看上去就正常多了吧。但是注意到,索引还是有问题。我们习惯上把第一根k线的索引设为10:00。因此我们就要用到第二个参数label了。看看文档描述。
label{‘right’, ‘left’}, default NoneWhich bin edge label to label bucket with. The default is ‘left’ for all frequency offsets except for ‘M’, ‘A’, ‘Q’, ‘BM’, ‘BA’, ‘BQ’, and ‘W’ which all have a default of ‘right’.
我英语也不是太好,所以没看懂啥意思,还是亲自试一下吧。
这回就对了
所以我们用下图总结一下这两个参数的作用:
当使用默认的closed='left', label='left'的时候,pandas就把9:30--9:59切割成一个bin,10:00-10:29切割成第二个bin,以此类推。计算第一个bin的时候,由于没有9:30的数据,pandas会默认构造一行全是NaN的数据行,但是使用agg聚合的时候,NaN不计算在内,所以从9:31起开始计算。label则使用第一条数据,也就是9:30的索引作为这个bin的索引。
而closed='right',则把9:31--10:00切割成一个bin,10:01-10:30切割成第二个,以此类推。label=right就使用这个bin的最后一条数据,也就是10:00的索引作为这个bin的索引。这样就完全符合我们平时的使用习惯了!
至此,我们做好了日k和30分钟k线,但是60分钟k线是不是也这么简单,使用rample("H", closed='right', label='right')就可以了呢?
很可惜,没那么简单,直接使用上面的代码做出来的k线如下图,这是错误的。因为我们A股的第一个60分钟是从9:30到10:30,而pandas做出来的是把9:30-10:00归类成第一个小时。10:00-11:00归类到第二个小时,这是自然的小时,这就和我们的小时线完全不一致了!
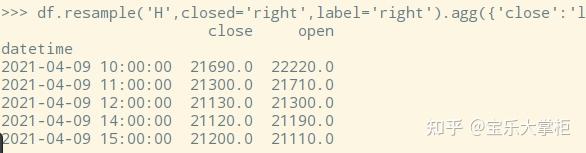
具体怎么做,有什么技巧,请看我的下期分享。
我是宝乐,一个有着7年it生涯,7年主观交易,2年多量化交易经验的交易员。我会不定期的分享工作中的各种干货知识,也希望和大家多多互动,向行业中的前辈们学习,共同进步。
标签组:[大数据] [pandas] [索引] [label] [bin]
上一篇:十五分钟级别K线的操作技巧
2021-04-30
2021-09-05
2021-06-04
2021-06-07

2021-05-16

2021-05-16
2021-05-16
Pandas技巧:轻松把1分钟股票数据转换成日k线、30分钟k线
2021-08-29
2021-06-04

2021-06-01

