发表自话题:k曲线怎么看
原标题:手把手教Stata做生存分析:K-M曲线绘制和Logrank检验
对于生存数据,1958年,E. L. Kaplan 和 Paul Meier 两位教授介绍了一种全新的、解决随访期间右删失 (right censoring) 问题的生存分析方法,被称作Kaplan-Meier方法。这种方法精确地记录并利用每个个体发生终点事件的具体时间,在任何一个终点事件发生的时间点计算出一个新的、基于之前所有信息的总生存率 (Cumulative survival) 。
相比于之前使用的寿命表法(Life-table method),这种方法更加充分地利用了信息,给出更准确的统计量。同时,作为一种非参数估计方法,不要求总体的分布形式,因此非常适合生存分析时使用。Kaplan-Meier 曲线(简称K-M曲线) 还可以很直观地表现出两组或多组的生存率或死亡率,非常适合在文章中进行展示。因此,K-M曲线也成为了临床研究中最常用的方法之一。
Why Stata?
Stata软件在进行生存分析的过程中具有很强大的功能。无论是 K-M曲线,还是Cox回归分析,甚至是一些更加复杂的参数分析,Stata都可以轻松完成。
相比于SPSS,Stata的可重复性更强,图像更加美观;而相比于R语言,Stata的代码又更加简便、易懂、上手快,甚至可以完全使用窗口菜单完成,非常适合有科研追求的医生入门。
今天,我们就一起来学习一下生存分析中的第一步、也是最重要的步骤之一:K-M曲线的绘制和Logrank检验。
我们将使用Stata自带的一个模拟的药物临床试验的数据集进行所有的演示,请大家在Command对话框中输入webuse drugtr以调入这个数据集。
屏幕显示:

请注意:Stata已经将这个数据集设置成了生存数据的格式,导入数据集后,请大家首先输入stset, clear命令恢复成普通的数据格式。这样才是我们在临床研究中见到的数据结构,我们将在Step 2中学习如何将其转换成生存数据格式。
Step 1 数据集的初步观测
首先,我们来观察一下数据集。大家可以在command line中输入list 查看所有数据,也可以输入list in 5/10查看第5到第10个观测值,屏幕显示:

我们可以看到,在这个数据集中,共有4个变量:studytime, died, drug, age。大家可以在command line中输入“codebook+空格+变量名字”,查看变量的标签、范围、是否有缺失值等基本特征。例如我们输入codebook drug, 屏幕显示:

我们可以看到共有48个数据,不重复的值有两个,分别是0 (安慰剂,从第一行的标签"Drug type (0=placebo)"看出来) 或 1 (试验药),没有缺失值。
同理,我们可以查看其它4个变量: studytime (标签:Months to death or end of exp. ,代表了这位患者的随访时间),died (标签:1 if patient died), age (标签: Patient's age at start of exp.)。
在基本了解数据后,我们可以正式开始数据分析了。
Step 2 声明数据为生存分析数据 & 数据再观测
Stata要求我们他这是一个生存分析的数据集,因此,我们需要至少告诉Stata如何判断终点事件(Failure variable)、如何判断随访时间(Time variable)。
在窗口菜单下,我们可以通过Statistics > Survival analysis > Setup and utilities > Declare data to be survival-time data找到如下的对话框。

在Time variable一栏选择数据集中的 "studytime"变量,在failure event一栏选择数据集中的"died"变量,并在Failure values的框中输入1。若多个值代表终点事件的发生,我们也可以在Failure values一栏输入多个值,每个值之间用空格隔开。
你可能会注意到,在Main菜单界面上还有一栏"Multiple-record ID variable"。Stata默认数据集中的一行数据代表一位患者。而在某些研究中,一位患者可能会有多行数据, 这一栏便是告诉Stata用哪个变量区分不同患者,通常选择数据集中代表患者ID的变量。然而,由于这种情况在实际的临床分析中并不常见,我们不详细阐述。在我们这个例子中,因为每个患者只有一行数据,我们可以不指定ID 。
点击OK后,屏幕上Results窗口内展示出如下画面。

如果你愿意使用代码,或者希望你的合作者能够重复你的结果,请使用上图第一行的代码:stset studytime, failure(died==1)。这是你在窗口菜单操作时Stata在背后执行的命令,我们也可以直接输入这行命令得到相同结果。
我们可以看到一共有48个患者,31人发生终点事件,共有744段person-time,随访时间最长的人是t=39。
使用stsum以及stdescribe命令,我们可以得到更多的关于这个数据集的信息。请注意:必须要在指定数据集为生存分析数据集之后 (换句话说,stset之后才能使用任何其他的st开始的命令)。
屏幕显示:

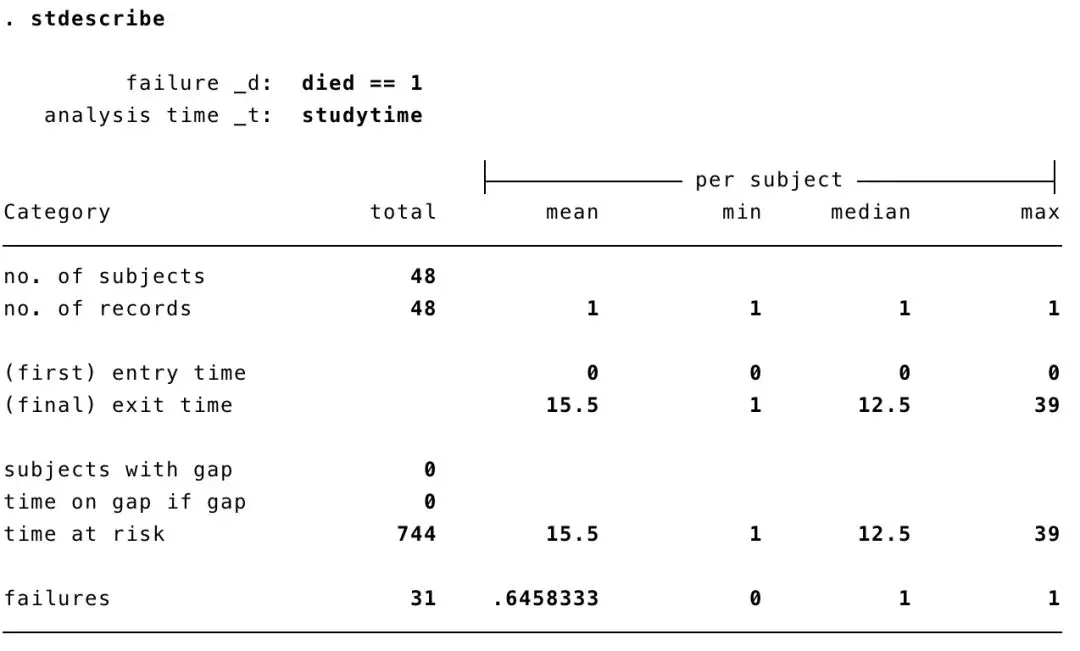
通过sts list命令可以展示Stata绘制K-M曲线所用的表格,我们可以看到每一个时间节点上的at-risk的人数、发生终点事件的人数、失访的人数,以及总的生存率。我们只展示前5行。
Step 3 K-M曲线的绘制
接下来,我们可以画K-M曲线。
在菜单栏中选择Statistics > Survival analysis > Graphs > Survivor and cumulative hazard functions,我们可以选择生存曲线(Function选项中Graph Kaplan-Meier survivor function) 或死亡曲线(Function选项中Graph Kaplan-Meier failure function),并且可以在下方Grouping variables处选择按照drug的数值分组绘图。

点击OK后,屏幕上会出现代码sts graph, by(drug)以及图像(下图)。

这是最基本、最简单的K-M曲线形式,在Stata中,我们还可以做很多改变,让图像变得更美观,表达更多的信息。
例如,在刚刚 Graph the survivor and cumulative hazard functions的窗口菜单中,利用第二个标签页(if/in)可以对数据库进行符合某种条件的筛选。例如我们只关注age

2021-05-31

2021-07-19
2021-10-10

2021-05-20

2021-06-01
真正的极品选股器—87.5%胜率的神奇牛百,测评结果+神奇九转幅图
2021-10-27

2021-10-27
vue 使用TradingView制作K线图(模仿火币)详解
2021-06-20

2021-06-01

2021-09-23

